How Session Rewind rapidly built an affordable session replay tool with Tinybird



It’s frustrating to read about analog industries where slow-moving incumbents still haven’t migrated from self-hosted data centers to the cloud. But it’s absolutely infuriating when even in the fast-paced software industry innovators refuse to adopt next generation technologies that would make their offerings more performant and affordable. The session replay industry has long been a prime example, so we decided to demonstrate how to rapidly build a session replay tool identical to the market leader’s at a 99% discount.
For those unfamiliar, session replay is the faithful reproduction of a user’s experience on a web application. It has become a ubiquitous capability for optimizing user experiences, monitoring front-end console errors, and facilitating real-time support. And yet, as any engineering team evaluating options for replaying a modest number of monthly sessions has unfortunately learned, it’s impossible to find a reliable solution that doesn’t have a restrictive trial or cost thousands annually. We think it’s price gouging, plain and simple.

Below are the economic and technical details about how we rapidly developed Session Rewind using the latest cloud technologies to put pricing pressure on market leaders.
Petabytes of data ≠ thousands of dollars
Accurate reproduction of a web session requires the initial DOM, linked files, network requests, and a detailed log of every change to the page triggered by user activity or scripts along with every user initiated event. Rather than re-running the scripts themselves - which may, among other concerns, present significant security risks - session replay makes use of the MutationObserver API, PerformanceObserver API, and browser developer tool APIs to capture their effects. For apps with significant interactive functionality this can add up to a lot of data, both in the number of events to process and in the sheer size (in bytes) of the information.
There wouldn’t have been many ways to build this a decade ago without using large and expensive ETL pipelines to buffer, process, and analyze the mammoth volume of data streaming in. The implementation would have required careful orchestration to scale up and down fleets of servers in response to variable demand. But that’s no longer true given the emergence of streaming data technologies like Kafka, scalable off-the-shelf load balancing solutions such as AWS’ API Gateway + EBS, and, more recently, lightning-fast analytical databases like ClickHouse.
By leveraging the latest technologies to minimize operational overhead, we knew that we could rapidly deliver accurate session replay at a fraction of the market’s current pricing.
To even further reduce our DevOps surface area, we introduced Tinybird’s realtime analytics platform built on top of ClickHouse. As one of Tinybird’s earliest customers while leading engineering at Feedback Loop, we knew their power, flexibility, and awesome developer experience would help us leapfrog the challenges inherent in storing and querying hundreds of billions of rows of analytical data.
The anatomy of efficient, modern session replay
We won’t go into every exhausting detail, but here are the main technical challenges we faced:
- High data throughput: As discussed above, building session replay required us to handle tens of thousands of requests per second, with significant variability (burst) in request volume.
- High data storage requirements with low retrieval rates: As we quickly discovered, a single session can contain MBs of raw DOM data, CSS, images, and events. Most of this, however, does not need to be queried and only needs to be made available for replay. Even for customers with 100k sessions in a month we expect that, on average, fewer than 1,000 will be replayed.
- Queries on arbitrary properties: Since session replay users expect to be able to search for events based on user-defined properties (for example, events from a customer cohort ID), a traditional relational database system would struggle to provide quick results without extensive (and expensive) indexing operations for each customer.
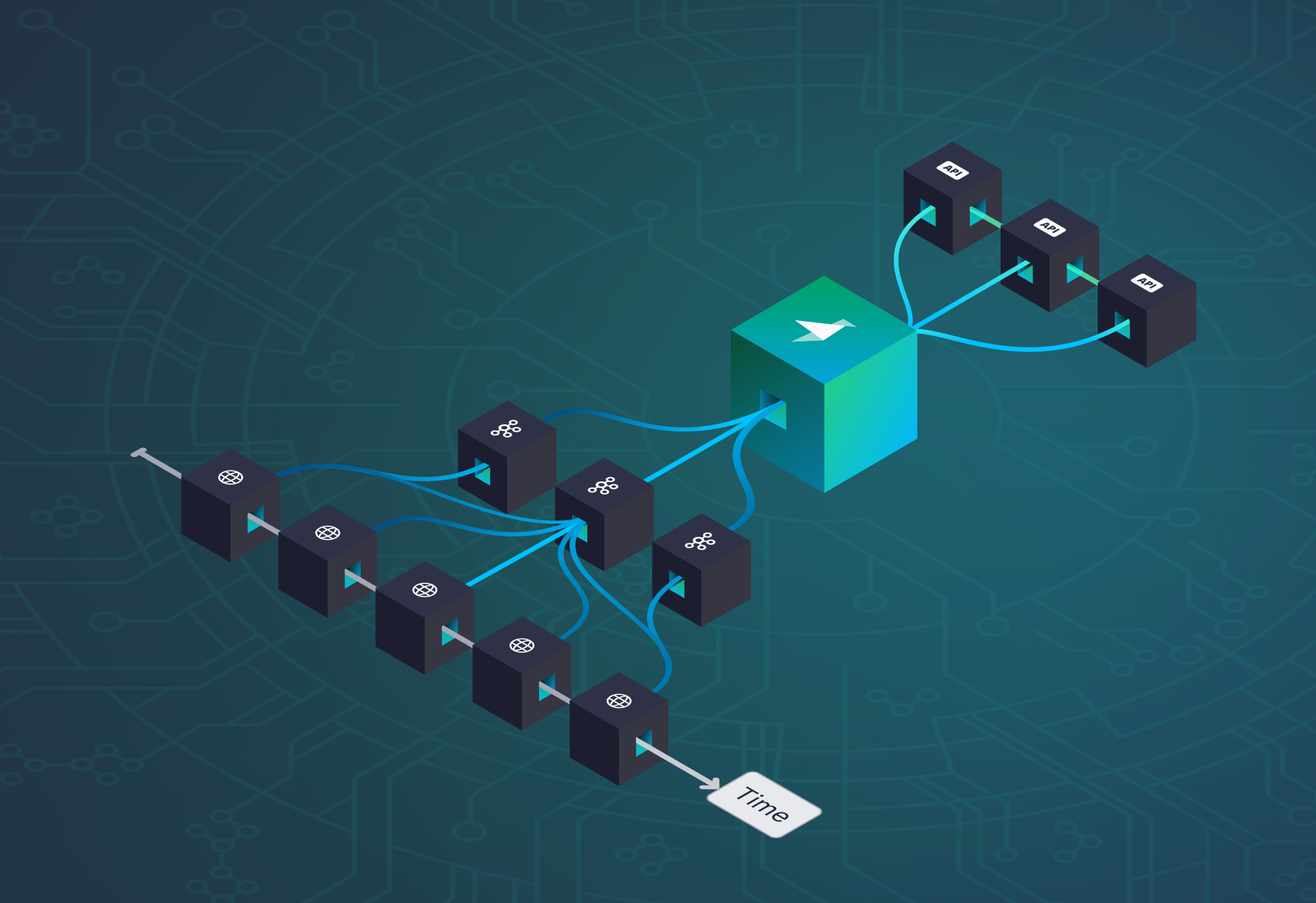
Again, for each of the above challenges, we focused on approaches that limited the technical surface area required to maintain ourselves and/or become experts in maintaining. For reference, the following diagram gives a high-level overview of our architecture.

We’ve omitted a few standard pieces of our architecture - a traditional PostgreSQL database for our low-throughput client data, a couple Redis instances, CDNs, etc - for brevity and because it’s well-trodden ground.
Solving for throughput
Handling massive throughput is a classic problem in web development, but the job is greatly simplified when the requests - in our case, made in the background while users browse your site - don’t require much I/O processing or data fetching. The primary challenge, ultimately, is choosing a database suited for high write volumes, since arbitrary reads aren’t needed at all.
Our other requirement was a guarantee that records would be written in the order received. We’d had success using Kafka in prior projects with similar requirements, so it was an easy choice. Kafka is known to be rather complex to configure and maintain, however, so we opted to host our cluster with Confluent Cloud, from the developers of Kafka. A single cluster from them can handle up to 2,048 partitions - the units needed for efficient parallelization - and data ingress of 100MB/s. That’s more than enough for our current needs, and we should be able to scale to multiple clusters in the future if needed.
To get data into Kafka, however, we needed producers. In our case we deployed a lightweight stateless producer server via AWS’ Elastic Beanstalk (EBS), which makes it simple to automatically scale up and down the number of servers based on demand. For some key endpoints we also added an API Gateway in front, since API Gateway provides free rate-limiting per API key, which is critical to ensure that our clients cannot exceed their plan limits and run up our infrastructure bill.
We then pipe the data into Tinybird’s Kafka consumer, which can nearly instantaneously process the data into more readily queryable formats.
You may be wondering: Why not just send the data into Tinybird directly? Until quite recently, Tinybird didn’t yet support high volume direct data input via API. Given that this is Kafka’s (and Confluent’s) bread-and-butter we also consider it to be the safer choice for resiliency in the short-term, but Tinybird has since released a high-frequency ingestion endpoint which we’ll certainly be testing in the future.
Solving for storage
While Kafka gracefully handles our concern for initially ingesting data, it’s a poor choice for data storage for a number of reasons. First, cost: Confluent Cloud charges $0.10 per GB per month for storage and $0.13 per GB for ingress. That’s almost 5x the cost of AWS S3 storage in S3’s most expensive Standard tier. Second, the Kafka clusters provided by Confluent have a maximum message size of 8MB, which is often exceeded by images and some DOM uploads, even after compression. Thankfully, the largest individual blobs of data that need to be stored for session playback - images, CSS files, initial DOM (and updates to the DOM) - don’t need their contents to be queryable for session playback.
Our approach here was to leverage S3 for all of the above, using our EBS servers to conditionally split the data out from events, sending the heavier data to S3 and dynamically replacing references to that data with their new location.
We discovered that a large chunk of the data we’d be storing in S3 was duplicative: images and CSS, in particular, change relatively infrequently. They do change, however, so we couldn’t rely on simply requesting a resource using its original file location during playback. To avoid storing the same image multiple times we built a simple caching engine based on file hashes and Redis to both properly identify duplicate files and ensure we don’t overload our users’ infrastructure.
In the future, we’re looking forward to experimenting with CloudFront’s upcoming R2, an S3 compatible object store which promises global distribution, lower storage costs, and free egress.
Lightning fast queries on arbitrary properties
Getting the remaining user event data into Tinybird was straightforward using their Kafka Data Connector and data ingestion engine. Where Tinybird really saved us time, however, is in prototyping the data extraction process.
Tinybird offers a Jupyter-like tool called Pipes that makes it easy to transform ingested data with chained SQL nodes. These nodes are like supercharged - and materialized - SQL views which you can quickly and safely iterate on and compose into larger or more complex queries. Any of the individual SQL nodes can optionally take in or require parameters, and the results can be made available via API with one click.

Some of our more complex data transformations took many iterations to optimize, and we were able to experiment with the different approaches simultaneously without impacting other experiments. Each SQL node in Tinybird provides useful metrics on its performance, which makes it trivial to pinpoint the source of problems in an API endpoint. Once we figured out the culprit we could test and fix it in isolation, swap out the old node for the new one, and click publish. Zero downtime updates with no backend changes on our end, like magic.
The iteration speed provided by Tinybird proved to be an excellent way for us to learn ClickHouse, the analytical database underpinning Tinybird. We can see why they chose to build on top of it - its ability to insert and query large volumes of data instantly is remarkable. Cloudflare famously replaced much of their analytics pipeline with ClickHouse to serve over 6 million requests per second.
At Session Rewind, we just needed to be able to quickly find sessions by arbitrary criteria, such as clicks on a given element ID. Our vastly more humble use-case proved to be no challenge whatsoever for Tinybird’s tuning of ClickHouse, serving up our most complex queries in well under 50ms, and often under 15ms. As we learn more about ways to tune our schema and optimize our queries further we suspect we’ll be able to eke even more performance.

What’s next?
Tinybird has been an excellent partner with us, offering tips on optimization and hands-on support as we rapidly add new platform functionality. With their help, we plan to achieve even lower pricing at scale while adding features for heatmaps, front-end error monitoring, funnel analysis, and more.
Thankfully, our ideologically-aligned friends at Coderbyte shared the go-to-market playbook they used to acquire 3,000 customers and successfully disrupt the technical assessment industry with a low-cost self-service solution. Using their marketing strategies, more than 50 companies (combining for 1m+ monthly sessions) have already discovered and began using Session Rewind, virtually all of which have switched from higher-priced SaaS alternatives.
Our strategy for building Session Rewind may not resonate with everyone. Relying on managed services for key infrastructure - and even functionality - is at times controversial, since they tend to bring with them some combination of higher cost and/or vendor lock-in. With enough headcount and budget it can be tempting to choose to bring your infrastructure management in-house, hosting Kafka and ClickHouse and the rest of the stack on bare EC2 servers, or perhaps your own data servers. In our opinion, large companies often build bloated software in order to justify headcount that otherwise has little else to do.
Our singular objective was to quickly deliver a market demand-validated product at a meaningfully lower cost. We managed to accomplish that as a side hustle for just two engineers and can easily scale without more resources. We believe a lot more software can and should be built with this lightweight approach!